Homeless in Vancouver: A reminder that Unicode fonts can still spell danger on the Internet
Out of the blue, a neglected, eight-year-old security vulnerability caused by the way the Internet supports multilanguage Unicode typefaces has resurfaced with a splash.
Two weeks ago, an information security researcher demonstrated how easy it was to still use Unicode font tricks to make malicious faked websites look safe and legitimate in modern web browsers.
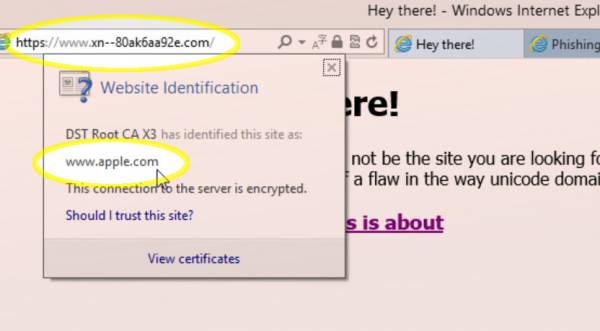
In an April 14 blog post entitled “Phishing with Unicode Domains”, security researcher Xudong Zheng showed off a one-page website he created using a properly registered domain name. When viewed in certain versions of Chrome, Firefox, and Opera, Zheng’s “proof of concept” website showed both a reassuringly secure and encrypted connection and one of the most trusted URL addresses in the world, namely “http://www.apple.com“!
Of course, the website had nothing to do with Apple and neither did the URL—it just looked that way.
The “аррӏе” of Zheng’s URL was made using characters from the Slavic Cyrillic alphabet—an alphabet included in every Unicode typeface. The Cyrillic characters and the order in which Zheng used them in just happen to bear a near-perfect resemblance to the Latin alphabet characters that spell “apple”, though the pronunciation of the Cyrillic “аррӏе” would be closer to “arr-eh”.
What Zheng had pulled off is well known among Internet security experts as a homograph attack, one exploiting the superficial resemblance between characters in different language scripts to fake website URLs.
More specifically it is called an IDN homograph attack, because it exploits the Unicode font support of the Internationalized Domain Name (IDN) system, which has allowed for the creation and registration of non-English domain (website) names for the last eight years.
However, before I go any further to explain the flaw that Zheng exploited, I want to quickly address his claim that certain web browsers are still susceptible to it—specifically that Mozilla (the makers of Firefox), when informed of the vulnerability in January of this year, decided not to issue a security patch and therefore that Firefox continues to be vulnerable.
A “proof of concept” proves not so dangerous after all

My personal tests with the eight web browsers that I have on hand confirm that Google Chrome was vulnerable until March 30 but not after that date, and that the Opera browser, up to the very latest version, is still vulnerable.
However, none of the Firefox versions I tested (going back to 2014) were fooled in the slightest, and even the aged Internet Explorer 10 (from 2012) didn’t actually fail.
Basically, only two of the eight web browsers I tested displayed the spoofed Unicode URL as “http://www.apple.com“:
- Chromium-based Opera, version 44.0 (since updated to fix this flaw)
- Google Chrome 57.0.2987.133 (March 30, 2017)

Six of the eight web browsers I tested safely displayed the spoofed Unicode URL in its non-Cyrillic ASCII form: “http://www.xn--80ak6aa92e.com“.
- Google Chrome 58.0.3029.81 (latest)
- Midori 0.5.11 (latest)
- Firefox-based Pale Moon 27.0 (2016)
- Chromium-based Vivaldi 1.0.435.42 (2016)
- Maxthon Nitro 1.0.1.3000 (2015)
- Firefox 28 (March 2014)
- Internet Explorer 10.0.9200.16843 (2012)
You can test whatever web browsers you use on Zheng’s proof of concept example.
Now back to the previously scheduled technical explanation, already in progress.
The perils of teaching an old dog new tricks
Unicode is an international standard created in 1991 for digital text, which recognizes a total of 128,000 characters covering 135 of the world’s modern and historic scripts. Most modern typefaces include only a fraction of the Unicode total—Arial, for example, contains a total of 27,720 characters, including special invisible ones to indicate things like a change in the reading direction.
The Unicode standard, when it came into being, only had desktop computers in mind. The Internet—which was a nearly 20-year-old U.S. government research project when the Unicode was being implemented—wasn’t even on the public radar yet and anyway, thanks to the age of its conception, the Net was already firmly based on U.S. English.
The Domain Name System (DNS), for example, gave every numeric server address on the Internet (email, ftp, website and so on) an equivalent, easier-to-remember (for people, at least) English-language domain name. It was drawn from a subset of the American Standard Code for Information Interchange (ASCII) character set—specifically the letters A through Z, the digits 0 through 9, and the hyphen character.
It wasn’t until 2009 that Internet domain names became truly multilingual (after a fashion) with the implementation of the Unicode Internationalized domain name (IDN) system.
Actually, all server address domain names are still based on the U.S. English ASCII character set. But just as the ASCII DNS system sits atop the numeric address system, so too the Unicode-based IDN system now sits atop the ASCII-based DNS system, with all Unicode domain names having an ASCII equivalent called a punycode.
To take Xudong Zheng‘s deceptive Unicode IDN as an example, the Unicode “http://www.apple.com” is converted by the DNS system into the ASCII-only punycode “http://www.xn--80ak6aa92e.com“, which is, itself, just a mask for a numeric address, such as “64.66.26.158”.
Using Unicode to bait a “phish”hook

Since the introduction of Unicode support to Internet systems in 2009, security experts have warned of a variety of ways in which Unicode typeface characters could be used for so-called “phishing” attacks.
Phishing is the term for fraudulent schemes to trick computer users into giving up sensitive personal data, usually by tricking them into downloading from the Internet and installing onto their computers disguised software, or “malware”, designed to secretly collect and transmit their passwords and credit card numbers.
A key to this kind of online con job is to use the most compelling clickbait email offers and/or trustworthy-looking counterfeit websites.
Beyond Zheng’s example, consider the word at the end of this sentence: “Раураӏ” It’s made of the following Cyrillic characters: “Er-a-u-er-a-palochka”. I dare you to distinguish it from the ASCII word “Paypal”.
Which is to reiterate that Unicode font support allows for the creation of some very convincing-looking fake domains of famous Western websites, using lookalike characters from non-Roman Unicode alphabets, such as Cyrillic but that’s not all Unicode offers would-be fraudsters.
In a 2015 post on Unicode spoofing tricks, I covered a range of possible Unicode homograph attacks, from website domain name spoofing—which may (or may not) still just be a speculative risk—to the well documented use of invisible Unicode RLO characters. These are designed to indicate changes of reading direction, to disguise dangerous malware programs as harmless picture files, in order to trick computer users into opening them.
Steps have been taken over the years to mitigate various vulnerabilities inherent in Unicode support. Web browsers will now always render domain names that mix Unicode and ASCII characters in their ASCII/punycode equivilent.
However, Zheng’s pure Unicode domain name was (and is) able to slip past some current web browsers. If nothing else, we have to hope that the fact serves as a wake-up call to the various browser makers to once and for all try to patch all the known security vulnerabilities presented by Unicode font support.
For my part, I’ll certainly be laying off using Opera until I hear that the still-glaring Unicode flaw in that browser has been patched.
Update: I didn't have to wait long! According to the Opera blog, Opera Stable 44.0.2510.1449 update, released April 25, "has been enriched with a security patch to prevent possible phishing with Unicode domains". The Opera blog even includes screen shots to show how the update now renders Xudong Zheng's fake Cyrillic Apple domain in its punycode equivalent.













Comments